
I Taught a Small LLM to Write Fiction. The Results Weren't What I Expected.
Tutorial and my thoughts on how we can optimise prompts for small LLMs to match quality of bigger one with DSPy and GEPA

In the rapidly evolving landscape of Large Language Models (LLMs), achieving high-quality, constrained text generation is a common challenge. While powerful models like GPT-5 or Gemini 2.5 Pro set a high bar, what if you could get similar quality from smaller, more efficient models? This post details an experiment where I tried to achieve that. We’ll walk through a hands-on project where I used the DSPy framework to optimize a Gemma-3-1b model for creative story generation with a novel optimization technique called GEPA.
Part 1 — Data preparations
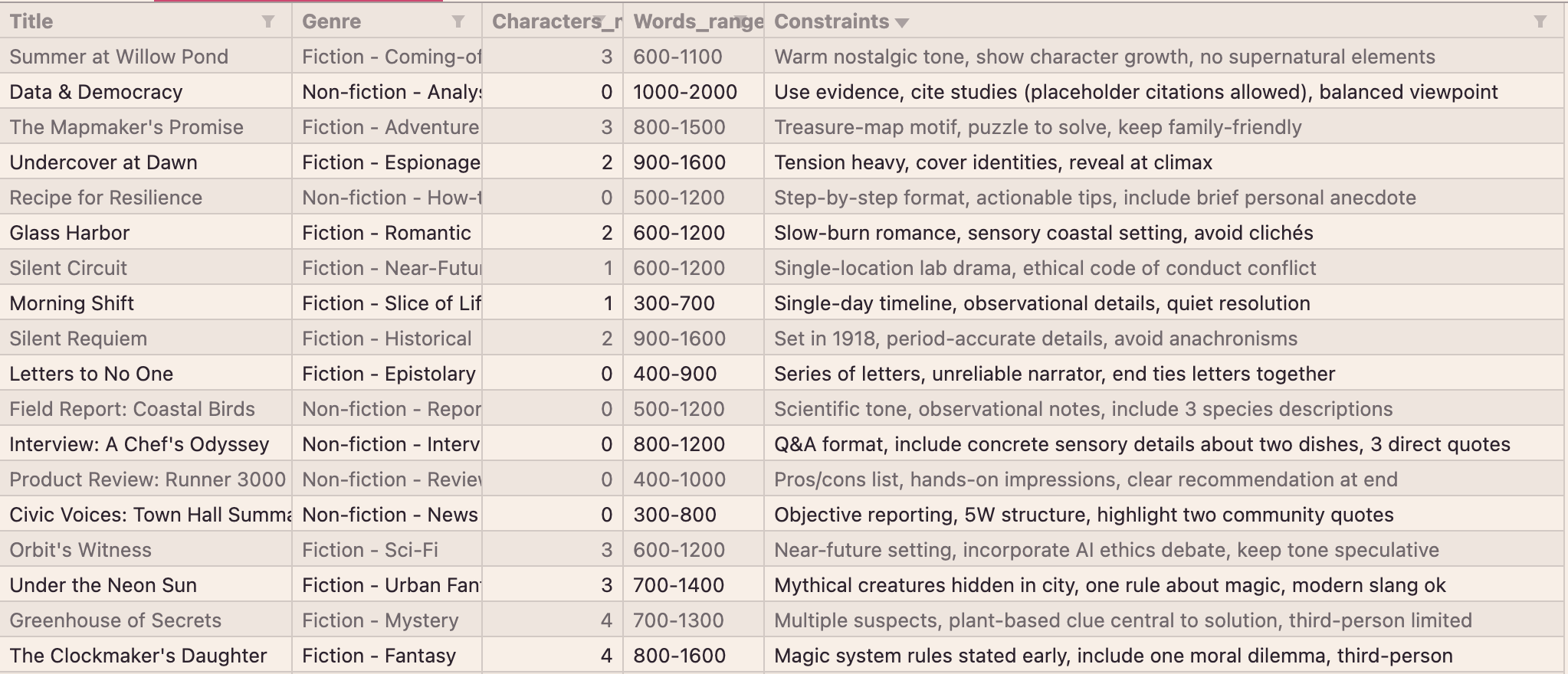
Every AI/ML project begins with data. For this experiment, I generated a dataset of 48 unique story ideas using ChatGPT. Each idea was structured with specific attributes to guide and constrain the story generation process:
title: The working title of the story.
genre: The specific genre, from “Fiction - Detective” to “Non-fiction - News.”
characters_number: The number of primary speaking characters.
words_range: A target word count, e.g., “800-1500.”
constraints: Specific narrative or stylistic rules, such as “First-person detective voice, one major twist, no gore.”
This structured dataset formed the basis for our training and validation sets.

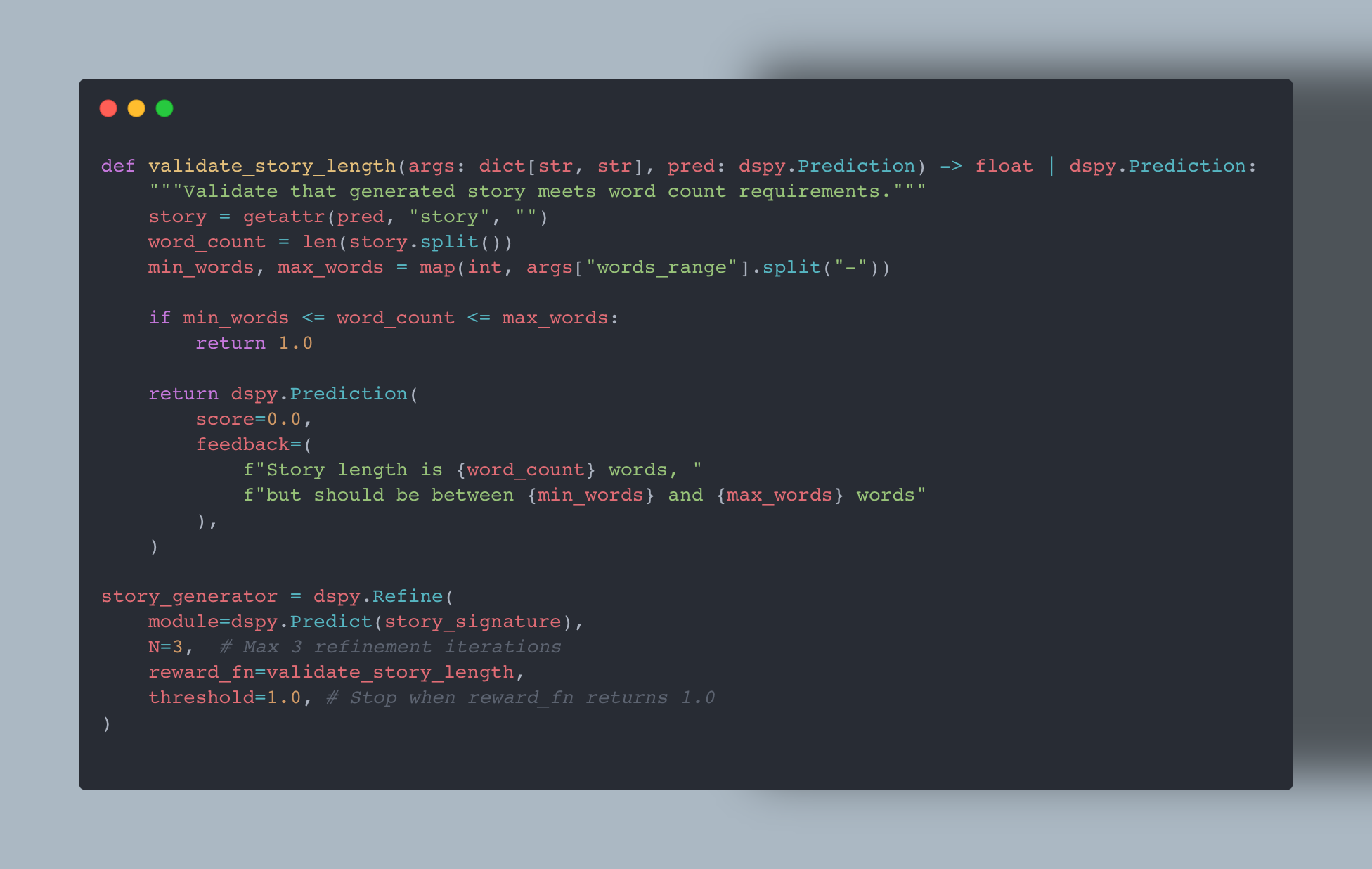
One of DSPy’s powerful features is dspy.Refine, which can iteratively improve a generation based on a validation function. While documentation often shows this with a simple score, you can actually return a dspy.Prediction object containing detailed feedback. This allows the model to understand why its output failed and how to correct it. I implemented a validator to check if the story’s word count fell within the required range.
This technique is highly effective but can be costly, as each refinement step is another LLM call. My goal was to use GEPA to bake this refinement capability directly into the prompt, reducing reliance on multi-step corrections.
Initial Model Outputs
To establish a baseline, I generated a story using three different models based on the following prompt:
PROMPT DETAILS:
Title: Last Light on Monroe Street
Genre: Fiction - Gothic
Characters: 2
Word Range: 800-1500
Constraints: Gloomy atmosphere, ancestral house motif, restrained horror
Gemini 2.5 Pro (The “Teacher” Model):
The taxi left them at the rusted gates, its red tail lights shrinking down the lane until they were swallowed by the evening gloom. Before them, the house on Monroe Street slumped against a bruised, lavender sky. It was less a building and more a monument to decay, its gables sharp as bone, its windows vacant as the eyes of a skull.
“It’s worse than I remember,” Julian said, his voice a thin thread in the oppressive quiet. He clutched the collar of his coat, though the air was merely cool, not cold.
Eleanor gave the peeling facade a pragmatic once-over. “It’s been empty for a decade, Julian. Houses don’t improve with neglect.” She pushed open the wrought iron gate, which screamed in protest, a long, scraping cry that set her teeth on edge…
Gemini-2.5-flash-lite
The rain had been falling for three days, a relentless, grey curtain drawn across the skeletal branches of the ancient oaks surrounding Blackwood Manor. Inside, the air was thick with the smell of dust, mildew, and the faint, lingering scent of lavender—a ghost of the mistress who had died here decades prior.
Eleanor clutched the brass candlestick, its metal cool against her palm. The single flame cast long, dancing shadows that made the ornate, gilded wallpaper seem to writhe. She stood in the main hall, a cavernous space where the silence was broken only by the rhythmic *drip-drip-drip* from a leak in the vaulted ceiling, marking time with agonizing slowness.
“Arthur?” she whispered, her voice swallowed instantly by the oppressive quiet…
Gemma-3-1b
The rain hammered against the windows of Blackwood Manor, a relentless rhythm mirroring the despair within. Elara Finch, a young woman burdened with a forgotten lineage and an unsettling sense of dread, inherited the ancestral house. The house itself seemed to watch her, its darkened hallways whispering secrets she desperately tried to ignore. She’d spent the last three days meticulously cataloging the house, surrounded by dust-covered portraits and decaying tapestries. She started to notice a pattern: the house’s architecture was meticulously crafted, almost deliberately designed to evoke feelings of melancholy. As she researched the Blackwood family history, fragments of dark folklore began to surface – tales of a cursed house and an unnatural darkness. She discovered that the last Blackwood heir, Silas, was obsessed with preserving a specific section of his family’s history: the diary.
The baseline from Gemma-3-1b is noticeably weaker. It tends to summarize or describe the premise rather than launching into a narrative. In many initial tests, it would simply repeat the prompt’s constraints, return only the title, or produce nonsensical text. This is the model we aim to improve.
Part 2 — The Judge and metrics
To optimize a model, you need a way to measure its performance. A simple “pass/fail” isn’t enough. I designed a multi-objective evaluation system with two key components.
The LLM Judge
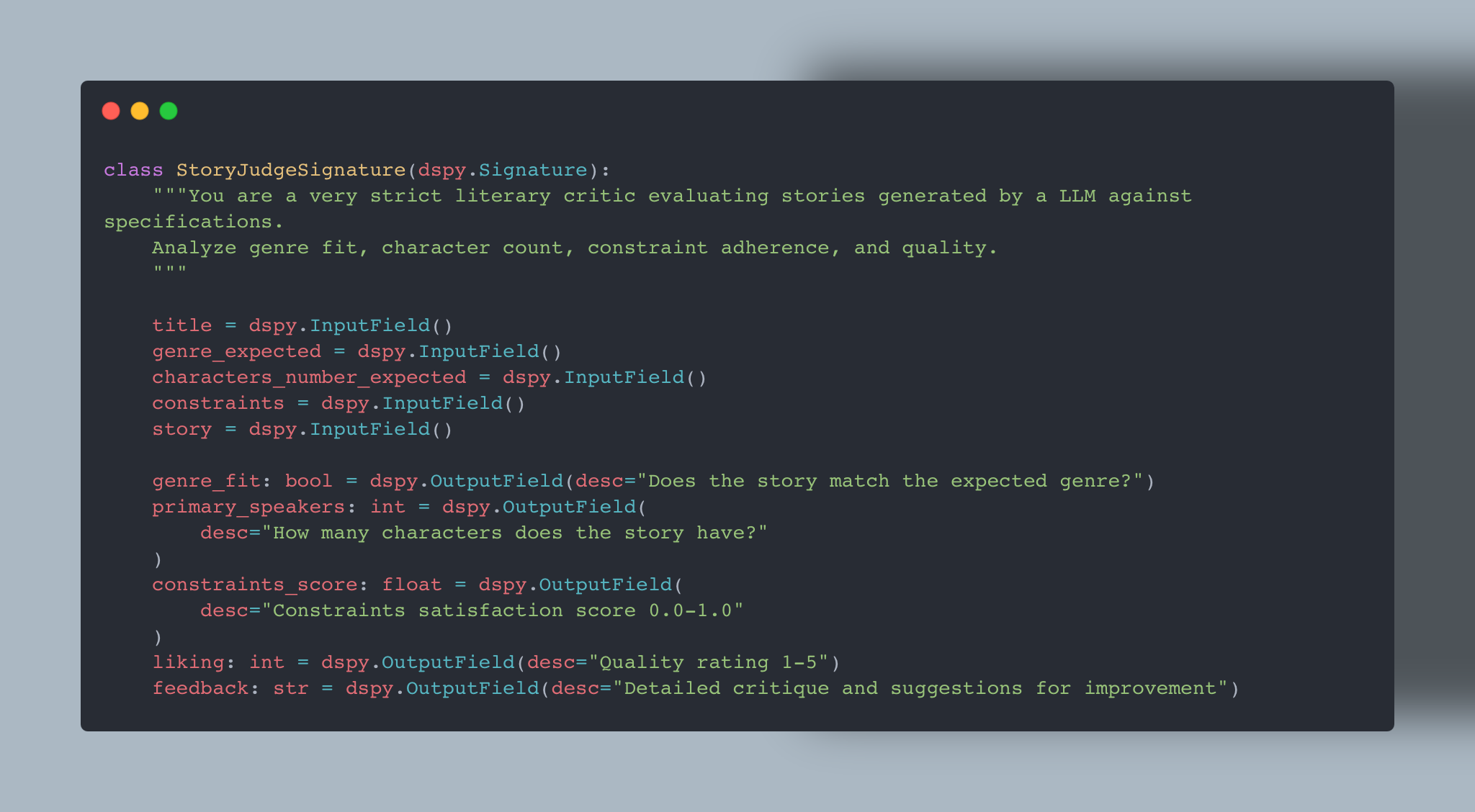
I created an AI critic StoryJudgeSignature in DSPy. This “Judge” is another LLM (run with a low temperature for consistency) tasked with evaluating the generated story against the initial requirements. It assesses multiple criteria:
genre_fit: Does the story feel like the requested genre?
primary_speakers: How many distinct characters are present?
constraints_score: How well were the specific constraints met?
liking: A subjective quality rating from 1 to 5.
feedback: A detailed critique explaining its reasoning.

Cosine Similarity with Sentence Transformers

To measure how semantically close the student model’s story was to the high-quality “teacher” story from Gemini 2.5 Pro, I used vector similarity. This technique works by converting each story into a numerical vector (an embedding) using a sentence-transformer library and calculating cosine similarity between them.
A score of 1.0 means the stories are semantically identical.
A score of 0.0 means they are completely unrelated.
My idea was that it would help us achieve a style much closer to the teacher’s reference.

A quick note on multithreading: Running embedding models within a multi-threaded training loop can cause issues. For this tutorial, I simplified by setting num_threads=1. In a production environment, a better solution would be to host the embedding model as a separate, asynchronous service.
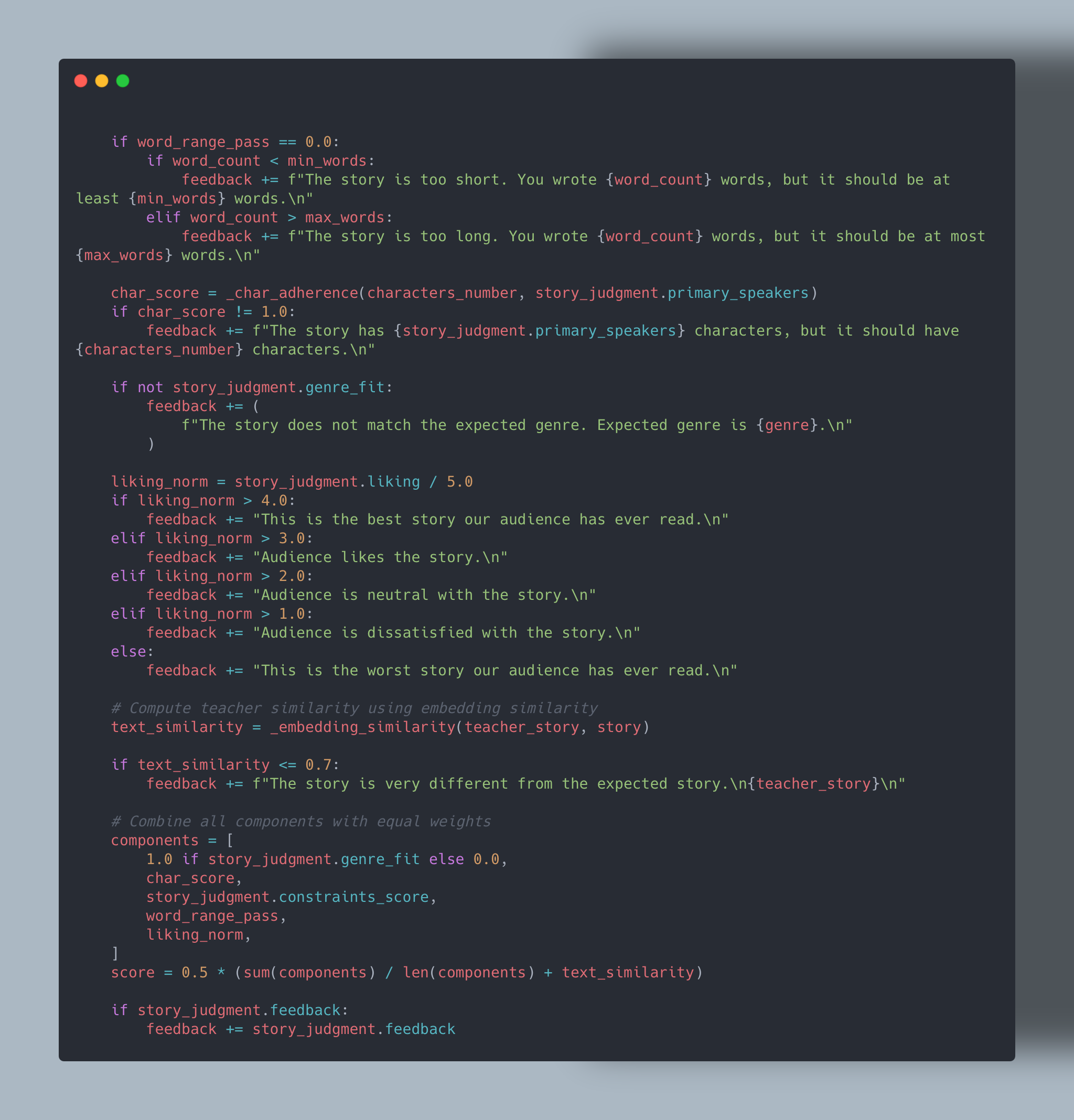
The Composite Metric: Importance of a feedback
Here’s where the system becomes really powerful. The metric doesn’t just return a score like 0.65 — it also generates detailed, human-readable feedback explaining why the score is what it is. For each metric, I define specific feedback for when issues occur. For example, if there’s a problem with word count, the system will report it — and the same applies to every other metric.
Possible problem: the LLM judge depends heavily on the quality of the LLM itself. For this experiment, I used Gemini 2.5 Flash Lite, and it seems to work well. However, a better LLM means a better judge.
Part 3 — GEPA Optimization and Results
What is GEPA?
From their GitHub:
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components—like AI prompts, code snippets, or textual specs—against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains.
But for me, it’s currently my favorite optimizer for projects. I recommend you to read their paper in your free time.
It’s very easy to configure GEPA optimiser. For tutorial I’m using auto="light", but if you want to get better results, it’s better to use "heavy". Full code you can find in my repository.
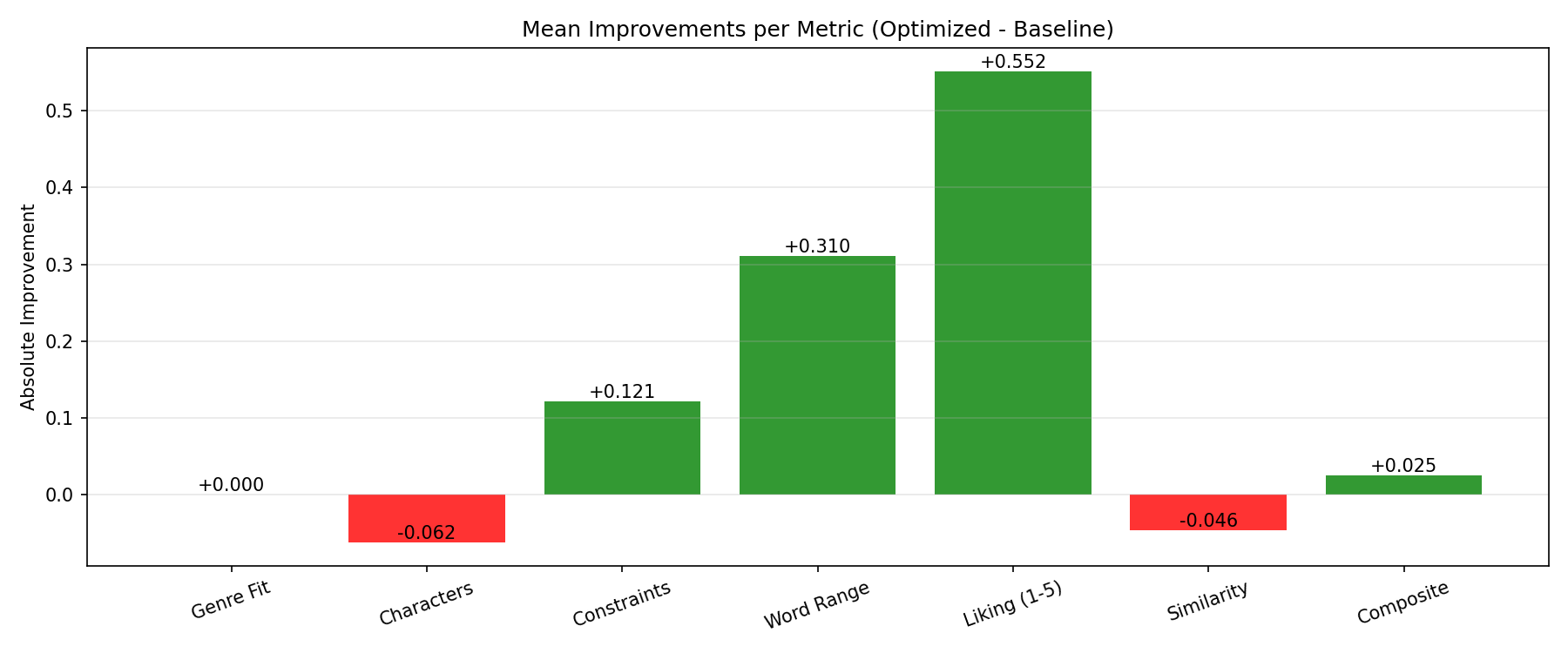
The metrics confirm our qualitative assessment. The most significant gains are in Liking (+0.552) and Word Range (+0.310). This is a huge win: not only is the model producing higher-quality content, but it’s also respecting structural constraints like length, which saves money and time on dspy.Refine calls.
But here’s the most surprising insight for me: the Similarity metric saw a slight decrease (-0.046). At first, this seems like a failure. GEPA didn’t teach Gemma to mimic the teacher model. I will research this in the future, but here is my thoughts on it:
Models Have Innate Styles: Every LLM has its own architectural biases, training data quirks, and “natural” way of writing. Forcing Gemma-3-1b to perfectly mimic Gemini’s exact phrasing and structure might be counter-productive. They might get close, but the result will feel strained and less authentic than if they were allowed to excel in their own style. You can event see it in how close styles of gemini-2.5-pro and gemini-2.5-flash-lite
Optimizing for the Whole, Not the Part: GEPA’s objective is to maximize the entire composite score, not just the similarity component. In its evolutionary search, it discovered that a certain style of prompt instruction led to huge gains in Liking, Constraints, and Word Range for Gemma. This new, highly effective prompt allowed Gemma to find its own “voice”—a way of solving the task that was optimal for its architecture. This optimal path for Gemma happened to be stylistically different from Gemini’s path.
Let’s look at one of the best results for Gemma:
The rain lashed against the stained-glass windows of Monroe Street, reflecting in puddles that mirrored the perpetual gloom within the old Victorian house. Eleanor Ainsworth, a woman meticulously cataloging her family’s collection of antique maps and photographs – a task she’d undertaken with an obsessive dedication – felt a growing unease as the house settled into a monochrome silence. Her grandfather, Elias Monroe, a renowned but largely reclusive collector of occult maps and symbols, had died just six months prior, leaving her the house and a mountain of fragmented records. The house itself seemed to whisper secrets – not pleasant ones – and Eleanor felt a persistent, unsettling presence.
It’s no longer a summary. The language is more descriptive, the atmosphere is present, and it adheres far better to the prompt’s intent. Still gemini-2.5-pro is better writer, but it’s really good result for small model.
But how does it look inside?
In the end we got the solid system prompt that can be used even in other LLMs. But it still better to optimise prompt for specific LLM.
You are a sophisticated literary and analytical AI…Your output must be a single, coherent piece of writing that strictly adheres to every instruction. Failure to meet any single requirement, especially `words_range` or `characters_number`, constitutes a failure of the entire task.
### Input Field Breakdown & Instructions:
1. **`title`**: Use this exact string as the title of your generated text. Do not modify it.
2. **`genre`**: This dictates the style, tone, and conventions of the entire piece.
* **`Non-fiction - Analysis`**: Write a formal, academic essay or article. The structure must include an introduction that presents a thesis, body paragraphs that develop distinct arguments with evidence, and a conclusion that summarizes and offers final thoughts. The tone must be objective and analytical.
* **Execution Example:** If asked to analyze \”Algorithmic Bias,\” you must move beyond a simple introductory paragraph. A successful piece would define the term, provide concrete case studies (e.g., the COMPAS recidivism algorithm, biased hiring tools), and then dedicate a significant section to discussing specific mitigation strategies (e.g., data auditing, fairness-aware machine learning models, regulatory oversight)…
Final Instructions:
Your primary goal is to synthesize all inputs into a single, high-quality, and **complete** text. A successful response is one where the genre, character count, length, and constraints are not just met, but work together harmoniously. Under no circumstances should you provide an incomplete story, an outline, or just the title. Generate the full text from beginning to end.
Part 4 — final thoughts
Did I achieve perfect results? Not quite. But progress is still progress. GEPA successfully transformed a small model that was struggling with a creative task into one that produces solid, usable drafts. We can also fine-tune our small LLMs — and in my opinion, that should be the way to go: first, we prepare optimized program-prompts, and only after that do we fine-tune the model’s weights.
Link to the full project: https://github.com/Archelunch/creative-optimisation-tutorial
I’m sure that we can have better ways on improving our results, improving metrics, judges.
Recently I found new paper “CLUE: Non-parametric Verification from Experience via Hidden-State Clustering” that replace LLM Judge and it also can be interesting to try.
What are your experiences with model and prompt optimization? Have you used DSPy, GEPA, or other techniques to solve similar challenges? Share your thoughts and questions in the comments below
Useful links:
DSPy: https://dspy.ai
GEPA: https://arxiv.org/abs/2507.19457
CLUE: https://huggingface.co/papers/2510.01591
sentence-transformers: https://sbert.net
Character sheet generator: my experiment with LLM optimisation for creative tasks where you can generate character for Fate Core ttrpg based on a prompt. https://github.com/Archelunch/fate-generator
PavlukhinLab — https://pavlukhinlab.com
If you like it, you can support me on https://buymeacoffee.com/mike_pavlukhin
Terrific write-up. Thanks for sharing.
At the risk of infinite recursive time-wasting, I wonder if GEPA could be used to tune feedback in the optimizer metric
that’s very useful, thanks! 👍🏻